Random Forests
Decision trees are easy to overfit to the original data; minimal changes to the original dataset can produce vastly different decision trees, meaning decision trees have high bias and low variance, making it difficult to predict out-of-sample values.
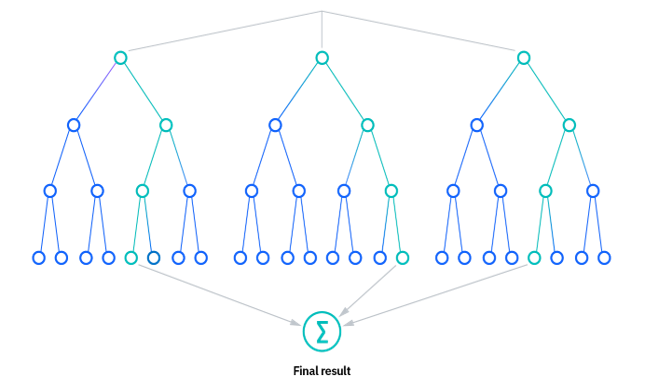
Random Forest is a versatile and widely-used ensemble learning method that operates by constructing a multitude of decision trees during training and outputting the mode of the classes (classification) or mean prediction (regression) of the individual trees. This approach enhances predictive accuracy and controls overfitting.
Random Forests reduce bias by employing three main strategies:
- Ensamble Learning: Combining the decisions from multiple models to improve overall performance
- Boostrapping: Training each decision tree on a random subset of the data (sampled with replacement) to reduce the variance
- Feature Randomness: Each tree is trained with a random subset of features, to reduce correlation between trees. If we chose the same features for every tree, the trees would end up looking very similar to each other, reducing the variance of the overall model.
When the Random Forest is built, and each decision tree has produced its output, the final output of the random forest is the aggregated output of all the decision trees:
- For classification tasks, each tree votes for a class, and the class with the majority votes is the final prediction.
- For regression tasks, the predictions from all trees are averaged to produce the final output.
In terms of feature importance, the feature importance of feature $f$ for the random forest is the average of the feature importance across trees, called Mean Decrease of Impurity (MDI).
How many features
It has been found that number of features close to $\log$ or square root of total number of features for each tree is the optimal subset of features to train a random forest model.
#machine learning #ml #machine_learning #programming #statistics #information gain #gini index #entropy #cart #classification #regression #bagging #boostrapping #aggregation #decision trees #ensamble