Decision Trees Classification
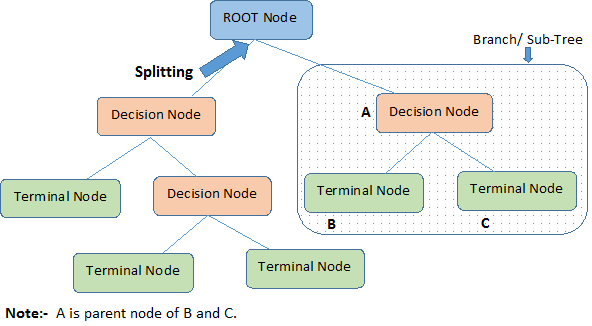
A decision tree is a supervised learning model used to predict the class label of instances by learning simple decision rules inferred from data features. It consists of nodes representing decisions based on feature values, leading to leaf nodes that denote class labels.
Building a Decision Tree
The process involves recursively splitting the dataset based on feature values to maximize the homogeneity of the resulting subsets:
- At each node, the algorithm evaluates all available features to determine the optimal split. The goal is to choose the feature that best separates the data into distinct classes. This is achieved using metrics like Information Gain or Gini Impurity
- Once the best feature is selected based on the chosen metric, the dataset is partitioned into subsets. This process is recursively applied to each subset, creating branches of the tree.
- The recursion continues until a stopping condition is met, such as:
- All instances in a node belong to the same class.
- No remaining features to split on.
- The tree reaches a predefined maximum depth.
Gini Impurity, Entropy and Information Gain
Gini Impurity measures the probability of incorrectly classifying a randomly chosen element if it was labeled according to the distribution of labels in the subset.
For a dataset D with C classes:
$$ G(D) = 1 - \sum_{i=1}^C p_i^2 $$where $p_i$ is the proportion of instances belonging to class $i$ in D
Information Gain measures the reduction in entropy (uncertainty) after a dataset is split on a feature. Entropy quantifies the impurity or disorder in the data.
Entropy
For a binary classification with classes $p$ and $n$:
$$ H(D) = -p \log_2(p) - n \log_2(n) $$Information Gain
The Information Gain of a split from node $N$ to nodes $N_l$ and $N_r$ is calculated as:
$$ IG(N, N_l, N_r) = H(N) - \frac{|N_l|}{|N|} H(N_l) - \frac{|N_r|}{|N|} H(N_r) $$From Scratch
1import pandas as pd
2import numpy as np
3
4
5def gini_impurity(y):
6 classes = np.unique(y)
7 impurity = 1.0
8 for cls in classes:
9 prob = np.sum(y == cls) / len(y)
10 impurity -= prob ** 2
11 return impurity
12
13
14def information_gain(y, y_left, y_right):
15 p = len(y_left) / len(y)
16 return gini_impurity(y) - (p * gini_impurity(y_left) + (1 - p) * gini_impurity(y_right))
17
18
19def split_dataset(X, y, feature_index, threshold):
20 left_mask = X[:, feature_index] <= threshold
21 right_mask = X[:, feature_index] > threshold
22 return X[left_mask], y[left_mask], X[right_mask], y[right_mask]
23
24
25class DecisionTree:
26 def __init__(self, max_depth=None, min_samples_split=2):
27 self.max_depth = max_depth
28 self.min_samples_split = min_samples_split
29 self.tree = None
30
31 def fit(self, X, y):
32 self.tree = self._build_tree(X, y)
33
34 def _build_tree(self, X, y, depth=0):
35 num_samples, num_features = X.shape
36 if (self.max_depth is not None and depth >= self.max_depth) or num_samples < self.min_samples_split or len(np.unique(y)) == 1:
37 leaf_value = self._most_common_label(y)
38 return {'leaf': True, 'class': leaf_value}
39
40 best_gain = 0
41 best_split = None
42 for feature_index in range(num_features):
43 thresholds = np.unique(X[:, feature_index])
44 for threshold in thresholds:
45 X_left, y_left, X_right, y_right = split_dataset(
46 X, y, feature_index, threshold)
47 if len(y_left) > 0 and len(y_right) > 0:
48 gain = information_gain(y, y_left, y_right)
49 if gain > best_gain:
50 best_gain = gain
51 best_split = {
52 'feature_index': feature_index,
53 'threshold': threshold,
54 'X_left': X_left,
55 'y_left': y_left,
56 'X_right': X_right,
57 'y_right': y_right
58 }
59
60 if best_gain == 0:
61 leaf_value = self._most_common_label(y)
62 return {'leaf': True, 'class': leaf_value}
63
64 left_subtree = self._build_tree(
65 best_split['X_left'], best_split['y_left'], depth + 1)
66 right_subtree = self._build_tree(
67 best_split['X_right'], best_split['y_right'], depth + 1)
68 return {
69 'leaf': False,
70 'feature_index': best_split['feature_index'],
71 'threshold': best_split['threshold'],
72 'left': left_subtree,
73 'right': right_subtree
74 }
75
76 def _most_common_label(self, y):
77 return np.bincount(y).argmax()
78
79 def predict(self, X):
80 return np.array([self._predict_sample(sample, self.tree) for sample in X])
81
82 def _predict_sample(self, sample, tree):
83 if tree['leaf']:
84 return tree['class']
85 feature_value = sample[tree['feature_index']]
86 if feature_value <= tree['threshold']:
87 return self._predict_sample(sample, tree['left'])
88 else:
89 return self._predict_sample(sample, tree['right'])#machine learning #ml #machine_learning #programming #statistics #information gain #gini index #entropy #cart #classification